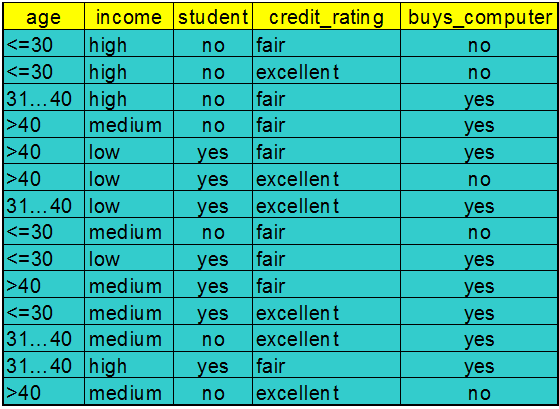
Training Dataset
This follows an example from Quinlan’s ID3
Algorithm for Decision Tree Induction
Basic algorithm (a greedy algorithm)- Tree is constructed in a top-down recursive divide-and-conquer manner
- At start, all the training examples are at the root
- Attributes are categorical (if continuous-valued, they are discretized in advance)
- Examples are partitioned recursively based on selected attributes
- Test attributes are selected on the basis of a heuristic or statistical measure (e.g., information gain)
Conditions for stopping partitioning- All samples for a given node belong to the same class
- There are no remaining attributes for further partitioning – majority voting is employed for classifying the leaf
- There are no samples left
Attribute Selection Measure: Information Gain (ID3/C4.5)
- Select the attribute with the highest information gain
- S contains si tuples of class Ci for i = {1, …, m}
- information measures info required to classify any arbitrary tuple
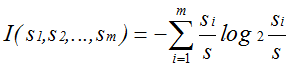
- entropy of attribute A with values {a1,a2,…,av}
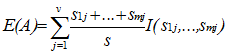
- information gained by branching on attribute A
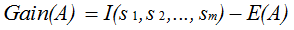
Attribute Selection by Information Gain Computation
- Class P: buys_computer = “yes”
- Class N: buys_computer = “no”
- I(p, n) = I(9, 5) =0.940
- Compute the entropy for age:
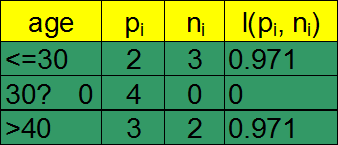
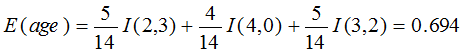
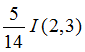
means “age <=30” has 5 out of 14 samples, with 2 yes’es and 3 no’s.
Hence
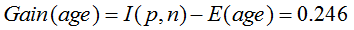
Similarly,
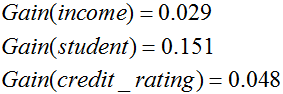
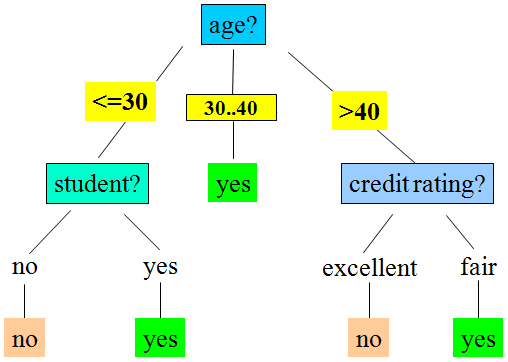
Output: A Decision Tree for “buys_computer”